
The Difference Between Installing an Agent and Building One

The other day I was talking to a coworker about his homelab.
He runs K3s at home and built a small agent that watches pod states. If something gets OOMKilled or falls into CrashLoopBackOff, it posts to Discord and restarts the pod. That’s it. Just automatic remediation.
Then I thought: that’s how agents are supposed to be built . They’re supposed to help us automate things. He has a framework for his system, a set of functions the AI can call, and he gets notified if something happens so he can intervene if necessary. This is the perfect way to take observability one step further and allow AI to take specific targeted actions to help.
The Homelab Mindset
I’ve noticed something recently. Before I started working on software professionally, people who had side projects on the cloud were the scrappy ones. They were learning more faster and that enabled their careers. Lately I’ve noticed a shift. Engineers who build homelabs are the more creative problem solvers; they just tend to think differently.
The cloud removes friction. It abstracts the hardware, the network, the blast radius. When something breaks in the cloud, it feels distant. When something breaks on your own system you are the ONLY one who can fix it. That changes how you design.
You are forced to think about failure before capability, containment before expansion, and recovery before autonomy.That mindset matters more in the age of AI than most people realize.
Hardware Is Back. That’s Good.
There has been an interesting resurgence in hardware lately, especially for Macs.
As OpenClaw and similar tools have taken off, I’ve noticed more and more people on Tech Twitter and other platforms buying machines specifically “for AI,” which part is exciting. Running things locally changes how you think.
If OpenClaw is what gets someone to buy a machine and start experimenting at home, that’s a net positive.
But we should be honest about something--running OpenClaw at home is not the same thing as home labbing.
Home labbing is about more than where the compute runs, it’s ultimately about ownership of the system. You need to understand the failure modes, and build something that’s tailored specifically to your use case. You need to be able to ask “what happens if I break this?” and then breaking it to answer your question.
OpenClaw — even when self-hosted — is still primarily a convenience layer. It is an installed autonomy. You are consuming a system someone else designed, not designing the boundaries yourself. That’s not inherently bad,.but it is fundamentally different.
The stereotypical movement I see around OpenClaw is not “I want to engineer a workflow.”
Rather, it’s “I don’t want to build an agent, so I’ll install one.”That mindset is the opposite of what home labbing teaches. Home labbing teaches us to build our own control instead of outsourcing it, and that distinction matters.
“What’s So Special About OpenClaw?”
So let’s address the elephant in the room. I have talked about it on my podcast and in several other blog posts because I live in an echo chamber where people all of the sudden quit talking about agents and started installing OpenClaw.
OpenClaw is not a magical agent harness. It’s just special because it’s convenient. The plugin ecosystem. The immediate feeling of autonomy without building the scaffolding yourself. It’sThat is powerful for non-technical users, .
but if you are a software engineer, convenience should not be the bar your reaching for.
Around the same time I was posting about this, Matt Sharp wrote about security — not because he wants to be “Mr. Security,” but because we are ignoring it in places we shouldn’t.
AI is one of those places.
That should make us uncomfortable.:
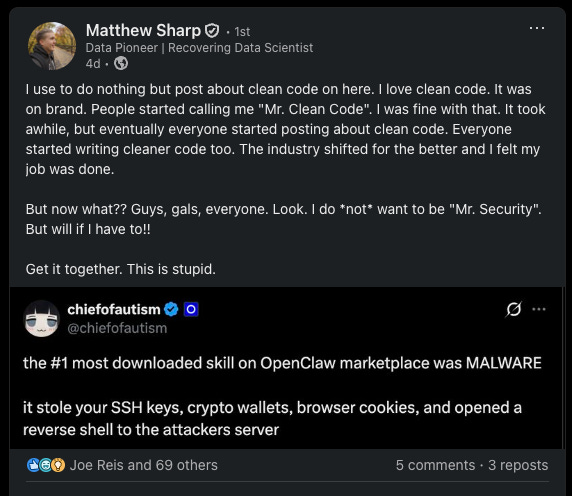
The most downloaded skilled on the OpenClaw marketplace turned out to be malware. It stole SSH keys, crypto wallets, browser cookies, and opened a reverse shell to an attacker’s server. And yet most of the conversation is still about what these agents can do — not what they can access, not how they can fail, and not how they can be exploited.
We are moving fast on capability and slow on security.
DeepAgent, LangGraph, and Control
If you compare something like LangChain’s DeepAgent or LangGraph to OpenClaw, the difference is not intelligence, it’s control.
DeepAgent and LangGraph force you to define state transitions, tool boundaries, and execution graphs explicitly. You encode what is allowed to happen and when, shaping the workflow itself.
OpenClaw feels different because you give it tools. You describe what you want and then trust the model to navigate correctly. The problem becomes that when most people use OpenClaw, they stop thinking about consequences.
Failure Modes
In reliability engineering, we assume failure and optimize for quick and seamless remediation. In security, we assume breaches and optimize for quick detection and countermeasures.
With AI agents, we assume success.
That is the flaw.
Right now I see too much implicit trust in AI and I rarely hear people ask what happens when the prompt is compromised. We hardly ever ask what happens when a tool call fails. We rarely ask what happens when the model confidently does spends my money for deletes files.
We assume it will recover because it “learns,” but models do not learn.
After training is completed, they only do probabilistic predictions. More instructions are not guardrails. It is just more tokens.
That is not remediation, it’s just a loop.
Security Is Remediation
Most real security work is remediation. You will have incidents. You will have edge cases. You will have abuse. The question is how you detect it, contain it, and recover.
Why are we treating AI systems as if they are exempt from that mindset?
If you install an agent internally and give it broad tool access, how are you thinking about blast radius? What is the rollback path? Who intervenes when it fails silently?
These are engineering questions.
Agents don’t eliminate failure. They eliminate busy work.
The Only Question That Matters
If you are deploying agents internally — whether it is OpenClaw, DeepAgent, LangGraph, or something you built yourself — there is one question that matters more than any other:
When it fails, what happens next?
That is the difference between engineering and hype.
What I Would Do Instead
Let’s dig in to this question.
If I were deploying agents inside a company tomorrow, I would not start with autonomy. I would start with boundaries.
The first thing I would define is scope. One workflow. One responsibility. One clearly defined success condition. Not “moderate Slack” or “manage Kubernetes.” It needs to be something narrow, observable, and reversible.
Then I would hard-code the state transitions.
The agent would not be free to decide what happens next. It would move through predefined stages:
Input → validate → call tool → validate output → log → exit

Every transition explicit, and every tool call wrapped in verification.
The model would generate suggestions, then the system would enforce decisions.
I would validate tool parameters before execution. I would validate outputs after execution. I would reject malformed responses. I would log everything. I would set blast radius limits at the infrastructure level, not the prompt level.
If the agent fails, it does not retry forever.
It escalates. If it escalates too often, it gets disabled.
That is remediation.
The model is not in charge of safety, the surrounding system is.
This is also why I self-host as much as I do. Not because I distrust enterprise providers, but because I understand they are not just exposing “raw models.” They are layering guardrails, fine-tuning adapters, evaluation harnesses, and enforcement mechanisms behind the scenes to meet customer expectations. They are engineering boundary conditions.
If you want production-grade behavior, you have to do the same.
In my own agents, I hard-code checks before and after model calls. I constrain which tools are callable, restrict parameter shapes, and I require structured outputs. I treat the model like an untrusted component inside a trusted system, because it is.
Prompts are guidance and code is enforcement.
Hard-coded guardrails are boring, but they’re the only thing I trust.
The companies that win with AI will not be the ones that install the most autonomy.
They will be the ones that engineer the cleanest failure paths.
Assume failure.
Stay Connected
Want to stay updated on what I’m working on? Here’s where you can find me:
Newsletter Highlights
Recent Posts You Might Have Missed
Upcoming Events or Streams
I’m also active in the Utah tech community. If you’re local, come build with us. Otherwise catch us on Twitch
Utah Data Engineering Meetup
https://www.meetup.com/utah-data-engineering-meetup/events/311227000/?eventOrigin=home_next_event_you_are_hosting
MLOps Utah Meetup
https://www.meetup.com/machine-learning-utah/events/312474910/?eventOrigin=home_page_upcoming_events$all
Latest Podcast Episode
Deep dives on AI infrastructure, home labs, and production engineering.
Latest episode:
What AI Hardware Should You Buy? Memory, Backends (CUDA/ROCm/Metal), and Scaling at Home | Ep 3
Then build.